Today I explored how to register a custom expression namespace in Polars. This feature turned out to be super helpful for solving a common problem I run into when building tables or plots—colorizing rows based on their row index.
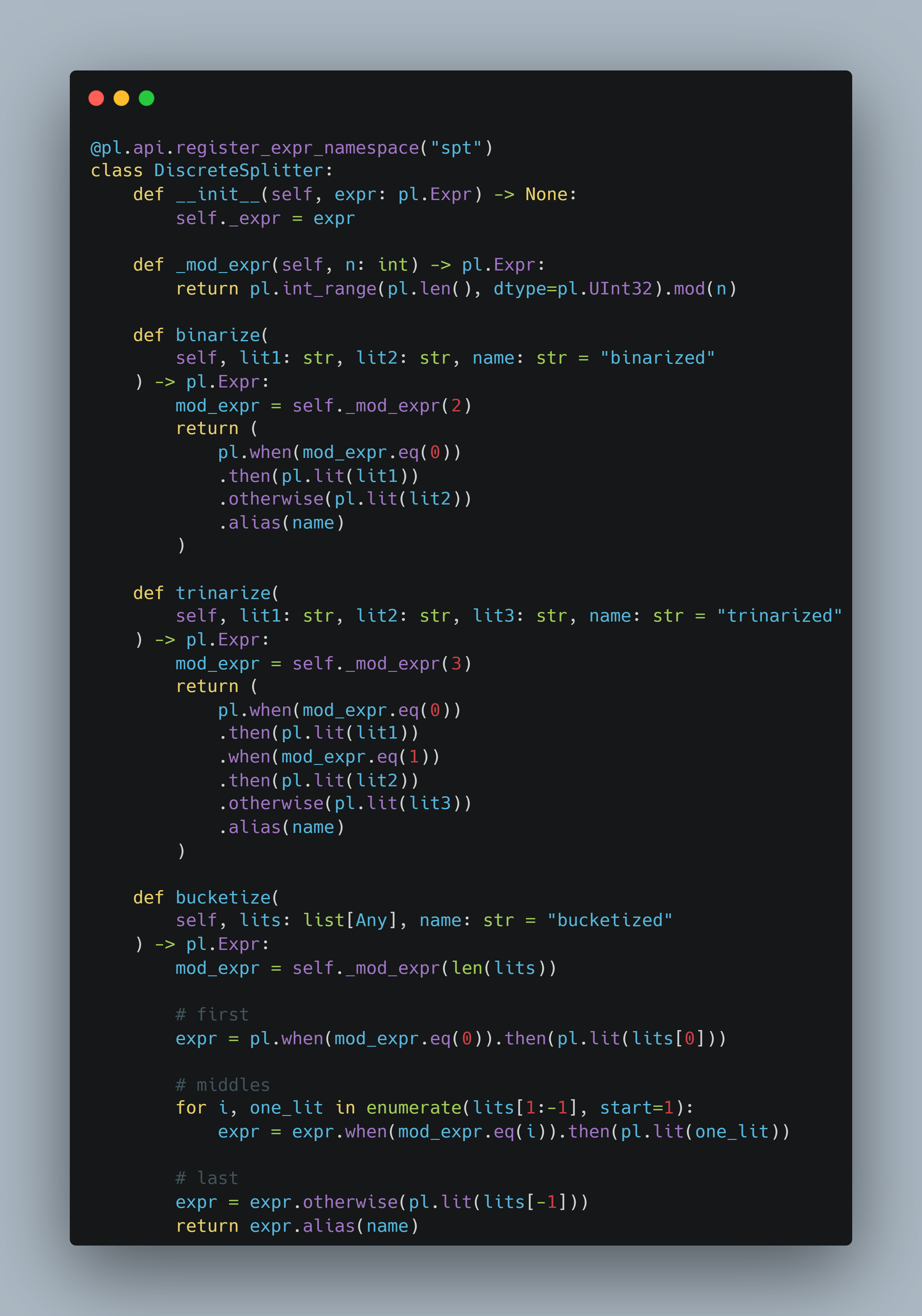
We use pl.api.register_expr_namespace() to attach our class to the spt namespace. Once registered, we can call our methods like this: pl.col("any").spt.binarize(...).
To assign values based on row position, we need a way to refer to the row index inside an expression. Polars provides a trick using pl.int_range(pl.len()), as shown in pl.DataFrame.with_row_index().
Note: Since the custom logic is based on the row index rather than actual column values, you can safely use pl.col("") as a placeholder when calling the namespace methods.
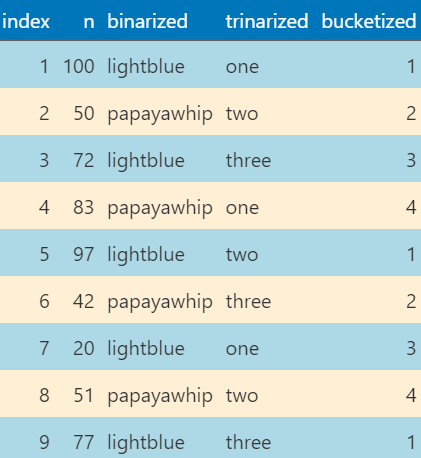
Each new column shows how rows are grouped using the row index modulo 2, 3, or 4—useful for highlighting patterns or applying styling.
For instance, you can use the binarized column with Great Tables like this:
Registering a custom expression namespace in Polars is a powerful way to encapsulate and reuse logic across your codebase. In this post, we created a DiscreteSplitter class to simplify index-based grouping, enabling operations like binarize, trinarize, and bucketize. This approach keeps your expressions clean and composable, especially when generating tables or plots that require styling based on row position.
It’s also worth noting that Polars supports similar registration for Series, LazyFrame, and DataFrame objects—check out the official documentation for more details.
Remark
Here’s a rough draft showing how to achieve a similar effect using the DataFrame namespace. I might revisit and refine this approach in the future.